Mudasser Shaik
I am a Principal BigData Engineer leading UKG.inc engineering team that develops highly scalable and fault-tolerant data ingestion and analytics platform.
I am currently a PhD Candidate at University of Arkansas at Little Rock with a focus on Data Quality, Data profiling and Deep Learning research.


Portfolio
- 👋 Hi, I’m @mudassershaik
- 👀 I’m interested in combining the powers of BigData, Information Quality and AI.
- 🌱 I’m currently learning probabilistic programing and GCP.
- ✨ I specialize in Apache Spark, Apache Beam, Hadoop and Kafka EcoSystem - Kafka-Connect-KStreams-kSQL.
- 💞️ I’m looking to collaborate on Streaming Systems, Data Initatives, ML-Ops.
- 📫 How to reach me - Slack
@Mudasser Shaik
Data Science
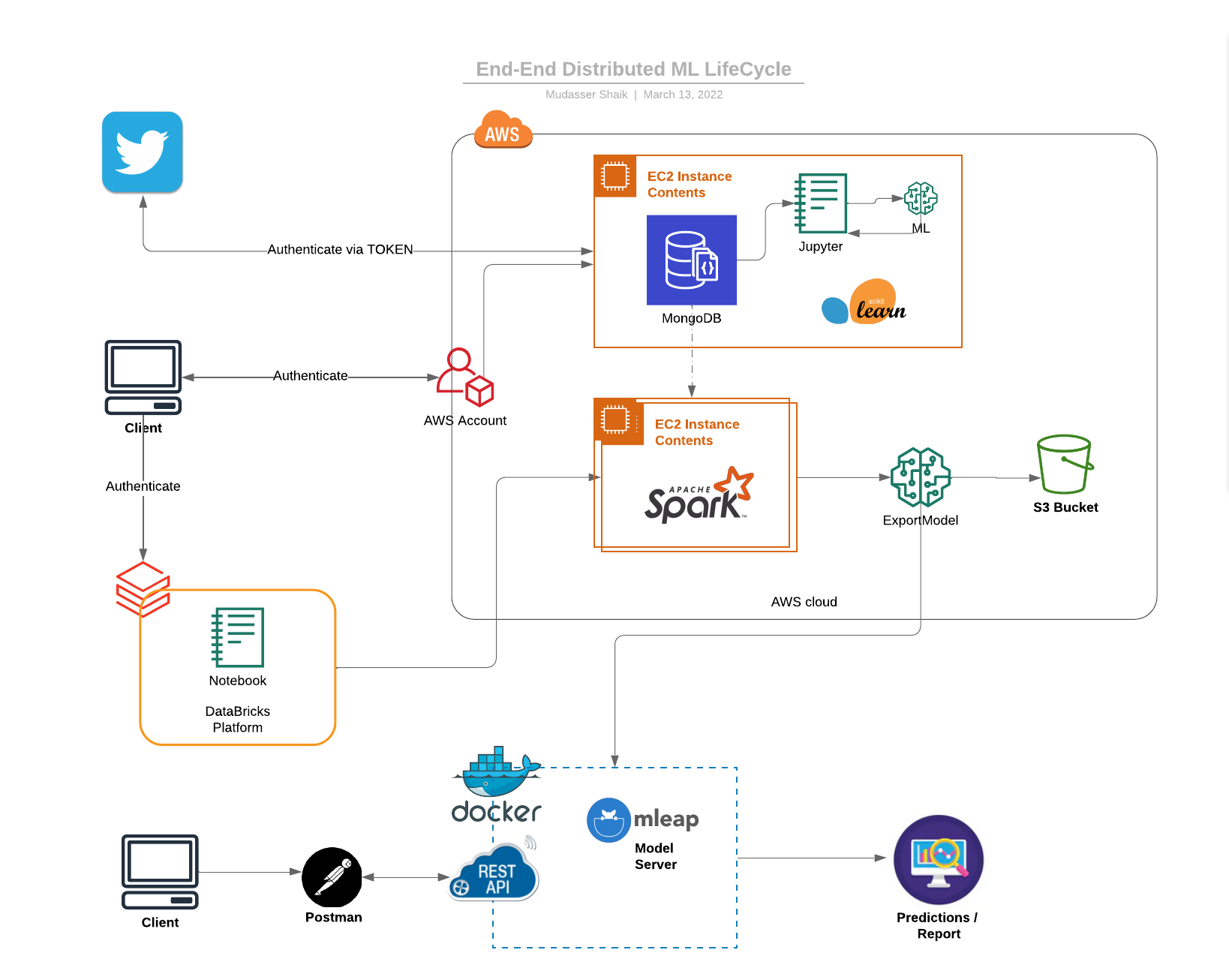
End-End Distributed ML LifeCycle
As an instructor, I designed and taught the curriculum for End to End Distributed Machine Learning workflow at Magnimind Academy. From created a python - Data crawler application that extracts, cleans and store the Twitter data into MongoDB to train and deploy a NLP classification Model to Docker.
- Data ingestion and Preprocessing using Python - Twitter Extractor
- Feature Engineering using PySpark-ML
- Model Training and Evaluation
- ML tracking using Apache MLflow
- Model Serialization using Apache Mleap
- Model Packaging and Deployment to Docker
- Schedule the training pipeline using Airflow
Spark Crash Course
After my team preprocessed a dataset of 10K credit applications and built machine learning models to predict credit default risk, I built an interactive user interface with Streamlit and hosted the web app on Heroku server.


Category Name 2
© 2020 Shaik Mudasser. Powered by Jekyll and the Minimal Theme.